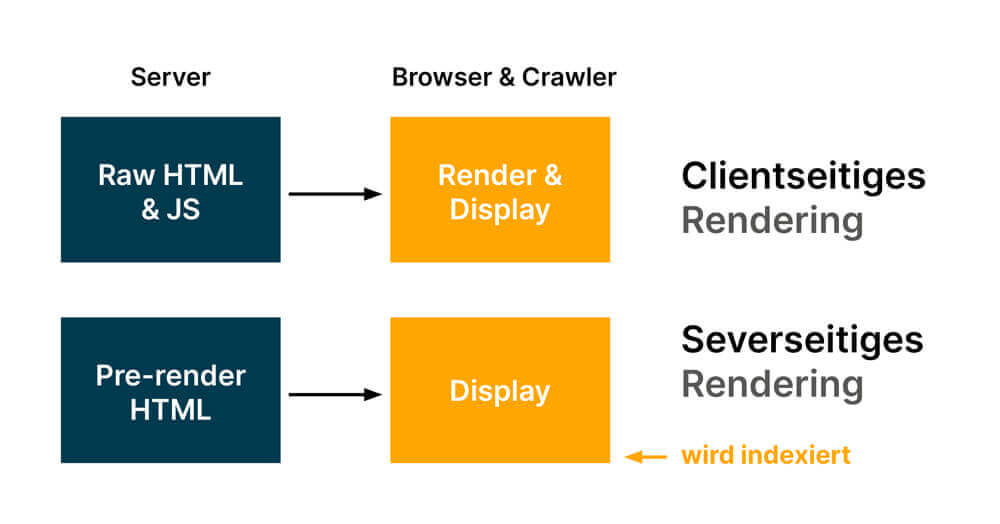
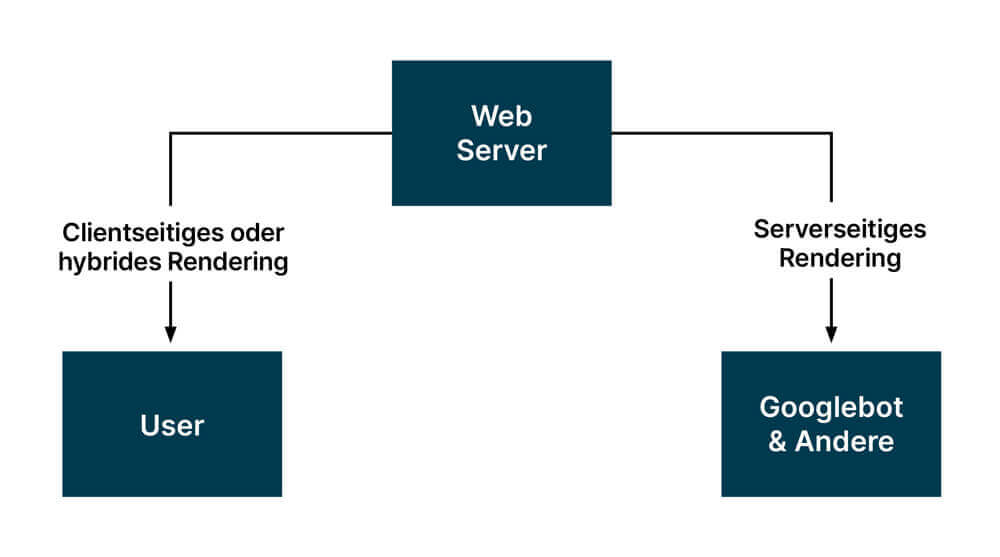
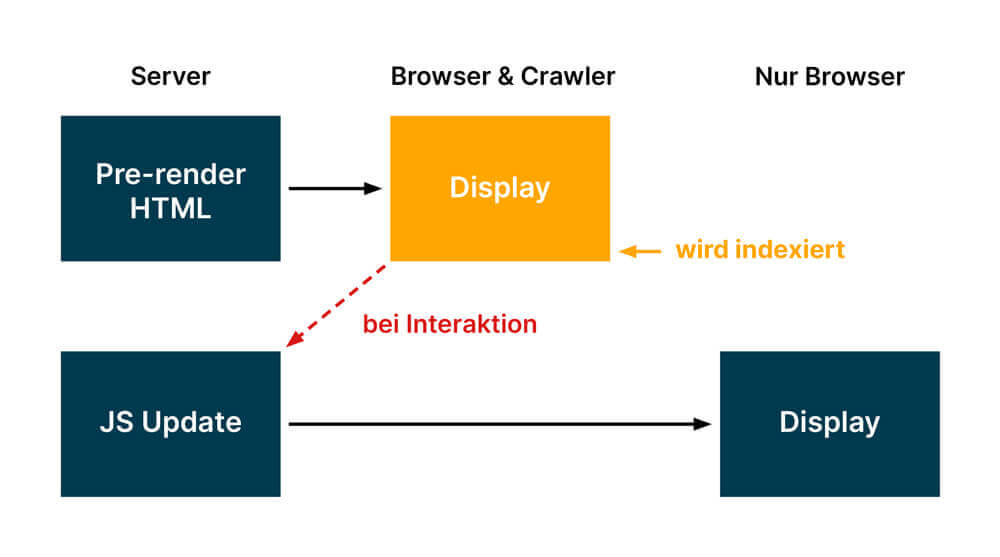
Auch wenn das Problem des Renderings oft die größte Herausforderung bei der Optimierung von JavaScript Seiten für Google & Co ist, tauchen oft weitere – aus SEO Perspektive gravierende – Probleme auf:
URLs
Mit JS-Frameworks lassen sich “Single Page Web Apps” realisieren. Dabei wird technisch eigentlich nur eine Seite als Container geladen. Alles weitere, Inhalte, Meta Tags usw. können per JavaScript nachgeladen und dynamisch verändern werden. Ganz ohne dass sich dabei die URL verändert. Für Suchmaschinen sind URLs aber nun man die Einheiten, die in der Suchergebnissen gelistet werden. Deshalb ist für SEOs auch immer wichtig, dass jeder Inhalt eine eigene, dauerhafte (und möglichst “schöne”) URL hat.
Daher müssen wir sicherstellen, dass immer wenn ein neuer Inhalt geladen, auch eine neue URL aufgerufen wird. Und zwar “normale” URLs und keine Hash-URLs (#) oder URLs mit Hashbangs (#!) – selbst wenn diese als Standard im Framework vorgesehen sind. Wichtig ist dann auch sicherzustellen, dass die URLs serverseitig unterstützt werden: Heißt, die einzelnen URLs müssen auch direkt aufgerufen werden können und nicht nur aus der Applikation heraus! Das ist wichtig, weil Suchmaschinen Crawler immer stateless operieren, also keine Cookies, LocalStorage, Service Workers, usw. verwenden.
Links
Suchmaschinen nutzen Links nicht nur dafür neue URLs zu entdecken, sondern auch um die Beziehung zwischen URLs herzustellen und damit PageRank, Autorität, Reputation oder wie immer man es nennen mag zu vererben. Für eine Verlinkung einer anderen URL sollte daher auch dafür vorgesehene HTML Anchor-Tag inklusive href-Attribut genutzt werden. Also ein klassischer Link gesetzt werden – auch wenn es mit JavaScript verschiedene Möglichkeiten gibt, URLs aufzurufen.
Meta-Tags enthalten wichtige Informationen für Suchmaschinen. Nicht nur das Robots Meta-Tag ist relevant, sondern auch Title, Description, Canonicals oder Hreflang Tags. Auch Social Media Bots ziehen Infos aus den Meta-Tags um die Previews in ihren Feeds zu generieren. Zu einer SEO Analyse gehört deshalb hier besonderes Augenmerk darauf zu legen, dass immer die passenden Meta-Tags zum tatsächlichen Inhalt ausgegeben werden.