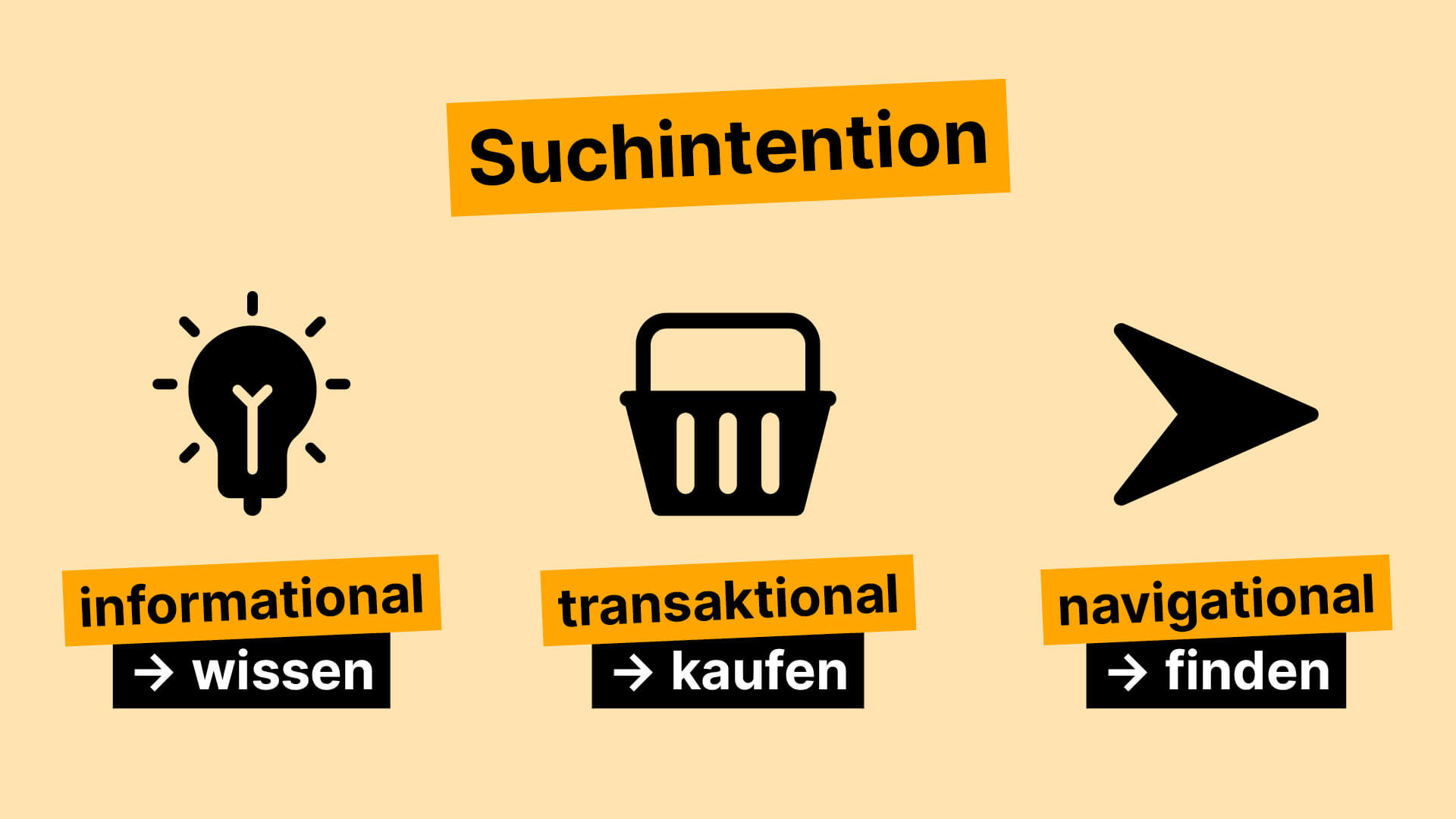
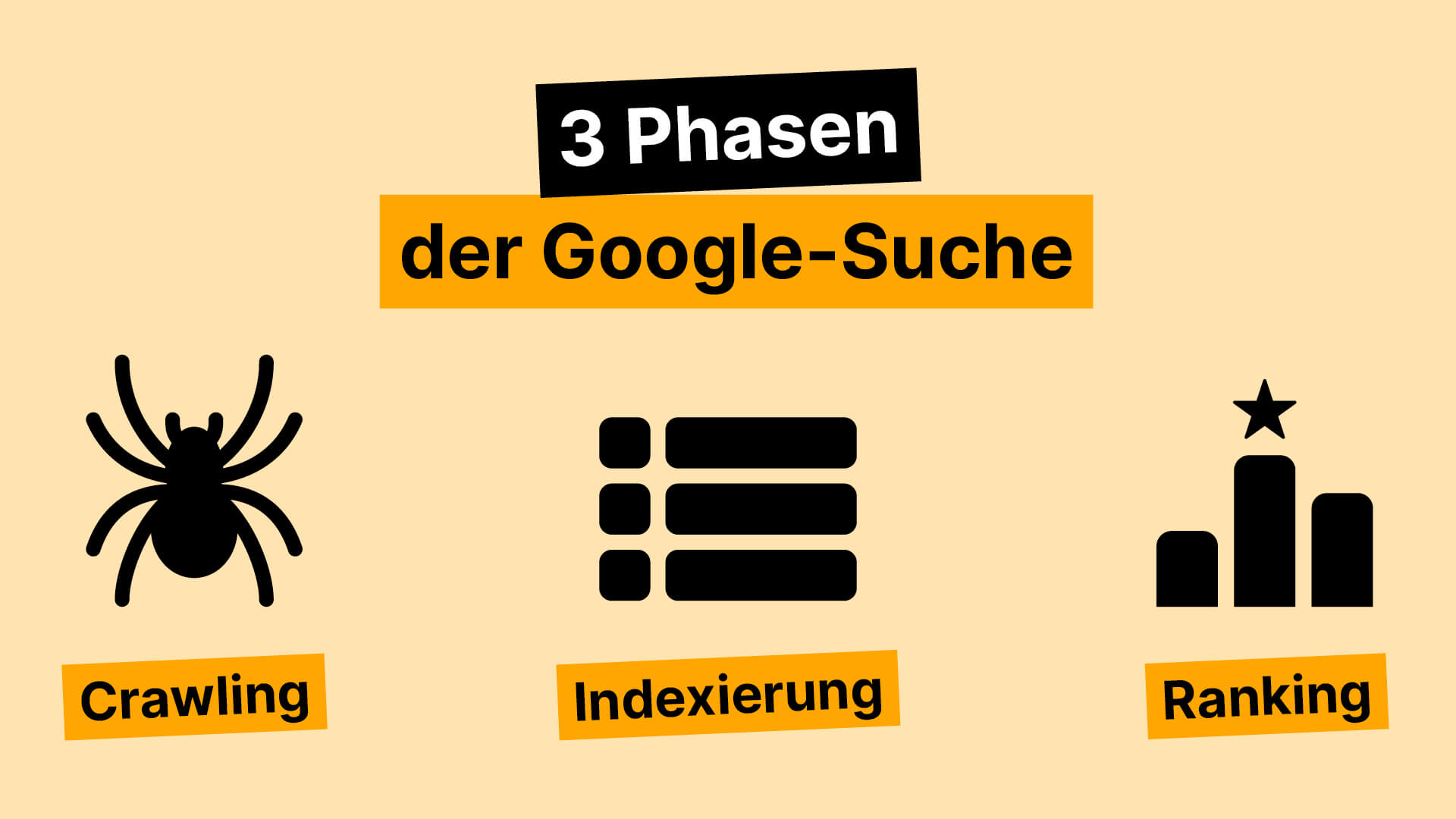
Damit eine Seite überhaupt in den Suchergebnissen erscheinen kann, muss sie zuerst einmal gefunden werden. Genau hier setzt der sogenannte Crawling-Prozess an, also der erste Schritt im Ablauf, wie Suchmaschinen Inhalte erfassen und bewerten.
Suchmaschinen wie Google schicken automatisierte Programme ins Netz, sogenannte Crawler oder Spiders. Der bekannteste davon ist der Googlebot. Dieser startet bei bekannten Webseiten und folgt dann sämtlichen Links, die er auf diesen Seiten findet – ähnlich wie jemand, der von einem Wikipedia-Artikel zum nächsten klickt. Jede neu entdeckte URL wird in einem riesigen Index – bei Google heißt dieser „Caffeine“ – gespeichert.
Ein praktisches Beispiel: Wenn ein Blogartikel von einem anderen, bereits bekannten Magazin verlinkt wird, hat der Crawler eine Brücke dorthin. Fehlt diese Verbindung, etwa bei neuen Seiten ohne externe Links, wird die Seite oft nicht oder nur verzögert entdeckt. Darum ist interne Verlinkung ebenso wichtig wie Verlinkungen von außen.
Aber nicht alle Seiten einer Website werden automatisch gecrawlt. Die Crawling-Kapazität pro Domain ist begrenzt. Google entscheidet also auch nach technischer Qualität und Relevanz, welchen Seiten Priorität eingeräumt wird. Fehlerhafte Links, langsame Ladezeiten oder unnötige Seitenvarianten (z. B. mit Parametern) können dazu führen, dass wertvolle Inhalte übersehen werden. Über die Datei robots.txt kann gesteuert werden, welche Bereiche einer Website gecrawlt werden dürfen und welche nicht. Wer etwa sensible Inhalte (z. B. Testumgebungen) vor der Öffentlichkeit schützen will, kann dies hier definieren.